diff --git a/README.md b/README.md
index 068c1762..39e507e1 100644
--- a/README.md
+++ b/README.md
@@ -10,9 +10,9 @@ TTS includes two different model implementations which are based on [Tacotron](h
If you are new, you can also find [here](http://www.erogol.com/text-speech-deep-learning-architectures/) a brief post about TTS architectures and their comparisons.
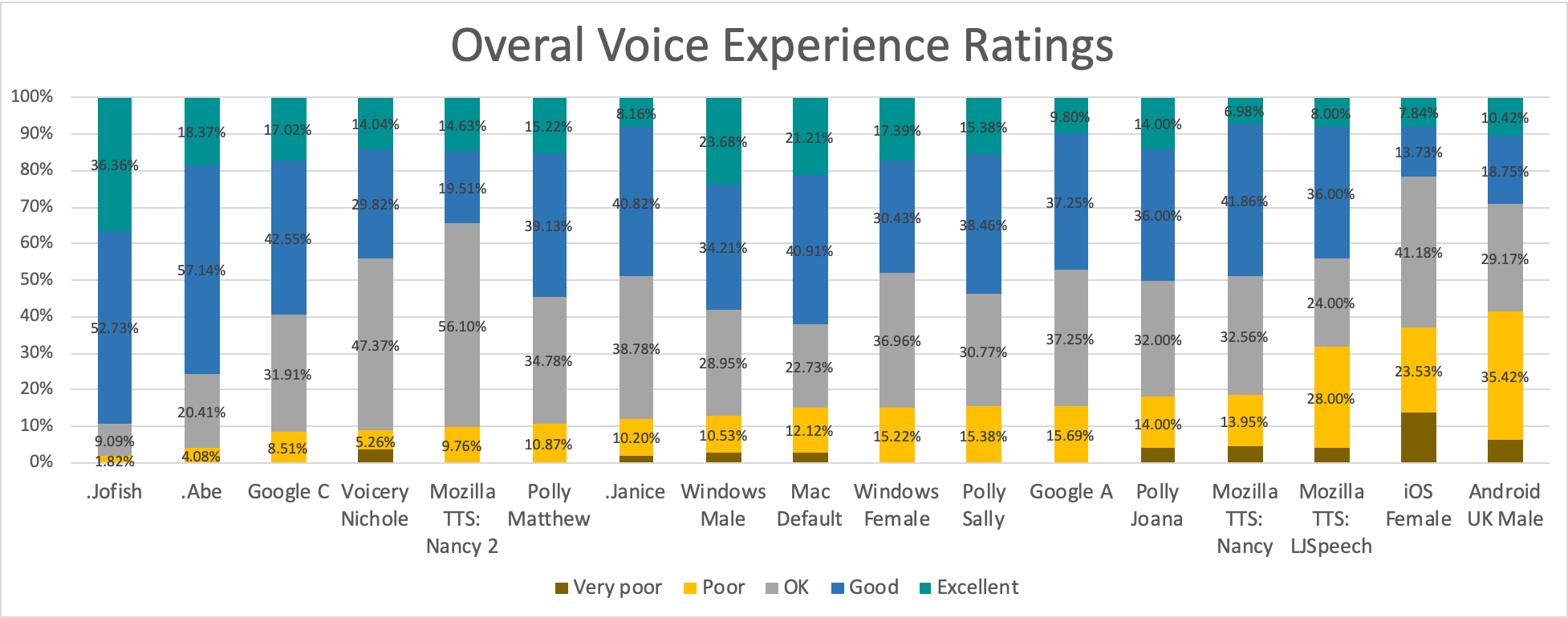
## TTS Performance
-
+
-[Details...](https://github.com/mozilla/TTS/issues/186)
+[Details...](https://github.com/mozilla/TTS/wiki/Mean-Opinion-Score-Results)
## Requirements and Installation
Highly recommended to use [miniconda](https://conda.io/miniconda.html) for easier installation.
diff --git a/config.json b/config.json
index 58e9b92b..2089c577 100644
--- a/config.json
+++ b/config.json
@@ -39,13 +39,13 @@
"warmup_steps": 4000, // Noam decay steps to increase the learning rate from 0 to "lr"
"memory_size": -1, // ONLY TACOTRON - size of the memory queue used fro storing last decoder predictions for auto-regression. If < 0, memory queue is disabled and decoder only uses the last prediction frame.
"attention_norm": "sigmoid", // softmax or sigmoid. Suggested to use softmax for Tacotron2 and sigmoid for Tacotron.
- "prenet_type": "original", // ONLY TACOTRON2 - "original" or "bn".
- "prenet_dropout": true, // ONLY TACOTRON2 - enable/disable dropout at prenet.
+ "prenet_type": "original", // "original" or "bn".
+ "prenet_dropout": true, // enable/disable dropout at prenet.
"windowing": false, // Enables attention windowing. Used only in eval mode.
- "use_forward_attn": false, // ONLY TACOTRON2 - if it uses forward attention. In general, it aligns faster.
+ "use_forward_attn": false, // if it uses forward attention. In general, it aligns faster.
"forward_attn_mask": false,
- "transition_agent": false, // ONLY TACOTRON2 - enable/disable transition agent of forward attention.
- "location_attn": true, // ONLY TACOTRON2 - enable_disable location sensitive attention. It is enabled for TACOTRON by default.
+ "transition_agent": false, // enable/disable transition agent of forward attention.
+ "location_attn": true, // enable_disable location sensitive attention. It is enabled for TACOTRON by default.
"loss_masking": true, // enable / disable loss masking against the sequence padding.
"enable_eos_bos_chars": false, // enable/disable beginning of sentence and end of sentence chars.
"stopnet": true, // Train stopnet predicting the end of synthesis.
@@ -55,7 +55,7 @@
"batch_size": 32, // Batch size for training. Lower values than 32 might cause hard to learn attention. It is overwritten by 'gradual_training'.
"eval_batch_size":16,
"r": 7, // Number of decoder frames to predict per iteration. Set the initial values if gradual training is enabled.
- "gradual_training": [[0, 7, 32], [10000, 5, 32], [50000, 3, 32], [130000, 2, 16], [290000, 1, 8]], // set gradual training steps [first_step, r, batch_size]. If it is null, gradual training is disabled.
+ "gradual_training": [[0, 7, 32], [10000, 5, 32], [50000, 3, 32], [130000, 2, 16], [290000, 1, 8]], // ONLY TACOTRON - set gradual training steps [first_step, r, batch_size]. If it is null, gradual training is disabled.
"wd": 0.000001, // Weight decay weight.
"checkpoint": true, // If true, it saves checkpoints per "save_step"
"save_step": 10000, // Number of training steps expected to save traning stats and checkpoints.