+

+
##

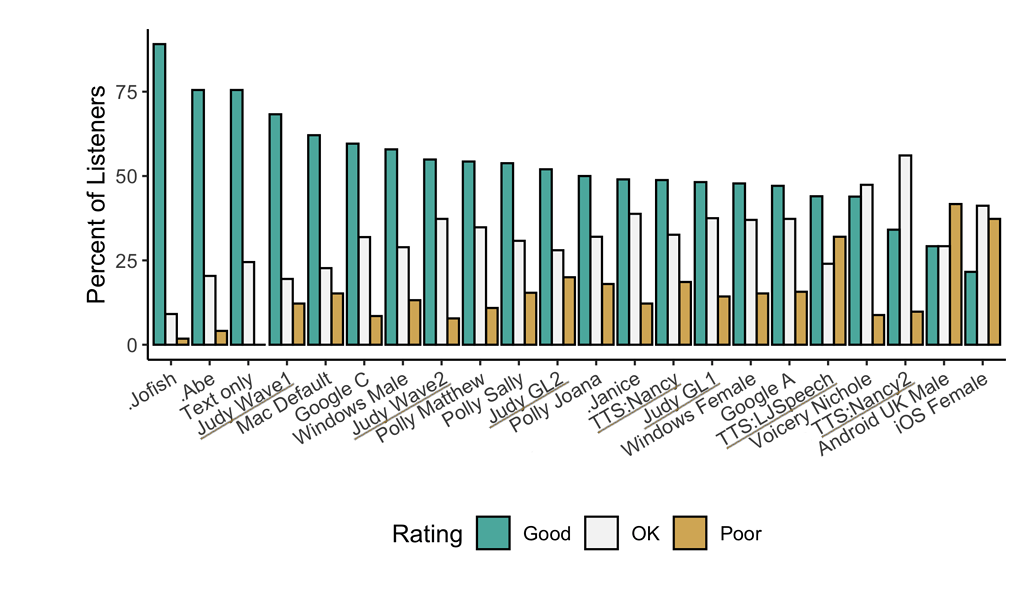
-🐸TTS is a library for advanced Text-to-Speech generation. It's built on the latest research, was designed to achieve the best trade-off among ease-of-training, speed and quality.
-🐸TTS comes with pretrained models, tools for measuring dataset quality and already used in **20+ languages** for products and research projects.
+**🐸TTS is a library for advanced Text-to-Speech generation.**
+
+🚀 Pretrained models in +1100 languages.
+
+🛠️ Tools for training new models and fine-tuning existing models in any language.
+
+📚 Utilities for dataset analysis and curation.
+______________________________________________________________________
[](https://discord.gg/5eXr5seRrv)
[](https://opensource.org/licenses/MPL-2.0)
@@ -36,13 +44,9 @@

[![Docs]()](https://tts.readthedocs.io/en/latest/)
-📰 [**Subscribe to 🐸Coqui.ai Newsletter**](https://coqui.ai/?subscription=true)
+