mirror of https://github.com/coqui-ai/TTS.git
5.8 KiB
5.8 KiB
🐸 Coqui TTS - Advanced Text-to-Speech Toolkit

A comprehensive library for advanced Text-to-Speech generation

![]()
![]()
![]()
📑 Table of Contents
- Latest Updates
- Quick Start
- Features
- Installation
- Basic Usage
- Available Models
- Advanced Usage
- Performance Optimization
- Deployment
- Contributing
- Community & Support
- Security
- Citation
🔥 Latest Updates
- 📣 ⓍTTSv2 released with 16 languages and improved performance
- 📣 ⓍTTS fine-tuning code available
- 📣 ⓍTTS now supports streaming with <200ms latency
- 📣 Support for ~1100 Fairseq models
- 📣 Integration with 🐶Bark and 🐢Tortoise View all updates
🚀 Quick Start
# Install TTS
pip install TTS
# Quick text-to-speech generation
python -c "from TTS.api import TTS; tts = TTS('tts_models/multilingual/multi-dataset/xtts_v2'); tts.tts_to_file(text='Hello, this is a test!', file_path='output.wav')"
✨ Features
- 🌟 High-performance Deep Learning models
- 🌍 Support for 1100+ languages
- 🎯 Production-ready performance
- 🔧 Easy-to-use API
- 📚 Comprehensive documentation
- 🛠️ Flexible training pipeline
💻 Installation
Requirements
- Python >= 3.9, < 3.12
- Operating Systems: Ubuntu 18.04+ (Primary), Windows, macOS
- GPU (Optional but recommended for training)
Basic Installation
pip install TTS
Development Installation
git clone https://github.com/coqui-ai/TTS
pip install -e .[all,dev,notebooks]
Docker Installation
docker run --rm -it -p 5002:5002 ghcr.io/coqui-ai/tts-cpu
📖 Basic Usage
Simple Text-to-Speech
from TTS.api import TTS
# Initialize TTS
tts = TTS("tts_models/en/ljspeech/tacotron2-DDC")
# Generate speech
tts.tts_to_file("Hello world!", file_path="output.wav")
Multi-lingual Voice Cloning
tts = TTS("tts_models/multilingual/multi-dataset/xtts_v2")
tts.tts_to_file(
text="Hello world!",
speaker_wav="path/to/speaker.wav",
language="en",
file_path="output.wav"
)
🎯 Available Models
Text-to-Speech Models
| Model | Languages | Speed | Quality | GPU Memory |
|---|---|---|---|---|
| ⓍTTS v2 | 16 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 4GB+ |
| YourTTS | 13 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 2GB+ |
| Tacotron 2 | Any | ⭐⭐ | ⭐⭐⭐ | 1GB+ |
| FastSpeech 2 | Any | ⭐⭐⭐⭐⭐ | ⭐⭐⭐ | 1GB+ |
🚄 Performance Optimization
Hardware Requirements
- Training: NVIDIA GPU with 8GB+ VRAM recommended
- Inference: CPU or GPU (2GB+ VRAM)
- RAM: 8GB minimum, 16GB recommended
Optimization Tips
- Use batch processing for multiple inputs
- Enable GPU acceleration when available
- Implement caching for repeated phrases
- Use quantized models for faster inference
🌐 Deployment
Production Setup
- Load models during initialization
- Implement proper error handling
- Set up monitoring and logging
- Use appropriate scaling strategies
Docker Deployment
docker run -d --gpus all -p 5002:5002 ghcr.io/coqui-ai/tts-gpu
🛠 Contributing
Development Setup
- Fork the repository
- Set up development environment
- Run tests:
pytest tests/ - Submit PR with detailed description
🤝 Community & Support
Get Help
Commercial Support
🔒 Security
Best Practices
- Keep models and dependencies updated
- Use environment variables for sensitive data
- Implement proper API authentication
- Monitor for unusual usage patterns
📚 Citation
@misc{coqui-ai-tts,
author = {Eren Gölge and others},
title = {🐸TTS - a deep learning toolkit for Text-to-Speech},
year = {2021},
publisher = {GitHub},
journal = {GitHub repository},
howpublished = {\url{https://github.com/coqui-ai/TTS}},
}
📊 Performance Benchmarks
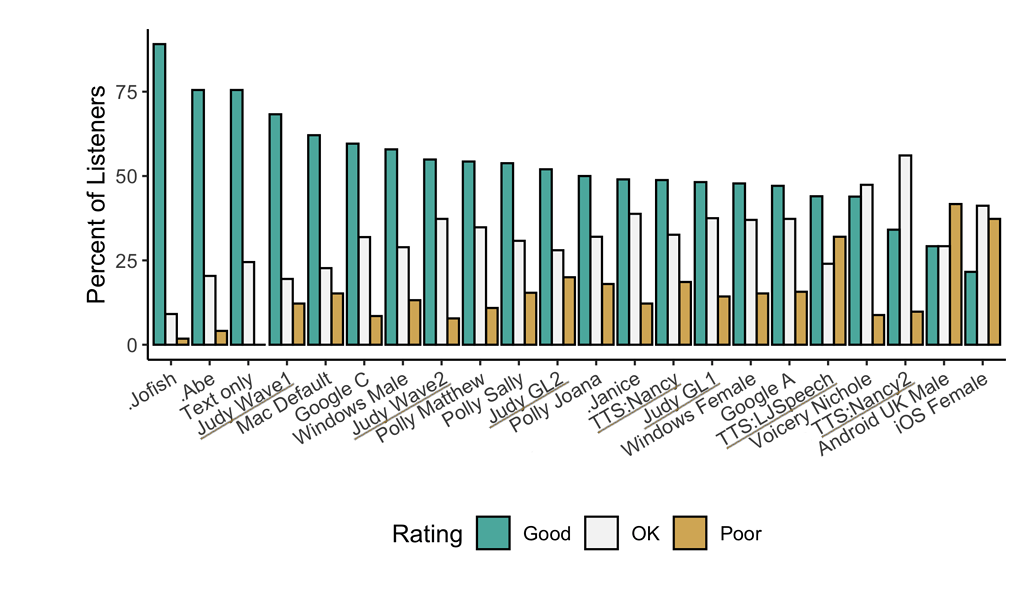
🌍 Language Support
- 16 primary languages with ⓍTTS v2
- 1100+ languages via Fairseq models
- Support for custom language training
📁 Directory Structure
|- notebooks/ # Jupyter Notebooks for examples
|- TTS/
|- bin/ # Training scripts
|- tts/ # Core TTS models
|- vocoder/ # Vocoder models
|- utils/ # Utilities
For more detailed information, visit our Documentation.